您现在的位置是:首页>网络营销>网络技术
数据爬取《实战Python网络爬虫》PDF+代码运行
![]() 王青召个人博客 2023-03-01 网络技术 91378人已围观
王青召个人博客 2023-03-01 网络技术 91378人已围观
简介聚焦网络爬虫又称主题网络爬虫,是选择性地爬取根据需求的主题相关页面的网络爬虫。与通用网络爬虫相比,聚焦爬虫只需要爬取与主题相关的页面,不需要广泛地覆盖无关的网页,很好地满足一些特定人群对特定领域信息的需求。增量式网络爬虫是指对已下载网页采取增量式更新和只爬取新产生或者已经发生变化的网页的爬虫,它能够
聚焦网络爬虫又称主题网络爬虫,是选择性地爬取根据需求的主题相关页面的网络爬虫。与通用网络爬虫相比,聚焦爬虫只需要爬取与主题相关的页面,不需要广泛地覆盖无关的网页,很好地满足一些特定人群对特定领域信息的需求。增量式网络爬虫是指对已下载网页采取增量式更新和只爬取新产生或者已经发生变化的网页的爬虫,它能够在一定程度上保证所爬取的页面尽可能是新的页面。只会在需要的时候爬取新产生或发生更新的页面, 并不重新下载没有发生变化的页面, 可有效减少数据下载量,及时更新己爬取的网页,减小时间和空间上的耗费,但是增加了爬取算法的复杂度和实现难度, 基本上这类爬虫在实际开发中不太普及。
数据爬取《实战Python网络爬虫》PDF+代码运行
《实战Python网络爬虫》PDF,483页;配套源代码。
下载: https://pan.baidu.com/s/1BbFejbRvbnbdu8YQum4Mqg
提取码: 3ww5
从原理到实践,循序渐进地讲述了使用Python 开发网络爬虫的核心技术。从逻辑上可分为基础篇、实战篇和爬虫框架篇三部分。基础篇主要介绍了编写网络爬虫所需的基础知识,包括网站分析、数据抓取、数据清洗和数据入库。网站分析讲述如何使用Chrome 和Fiddler 抓包工具对网站做全面分析;数据抓取介绍了Python爬虫模块Urllib 和Requests 的基础知识;数据清洗主要介绍字符串操作、正则和BeautifulSoup的使用;数据库讲述了MySQL 和MongoDB 的操作,通过ORM 框架SQLAlchemy 实现数据持久化,进行企业级开发。实战篇深入讲解, 了分布式爬虫、爬虫软件的开发、12306 抢票程序和微博爬取等。框架篇主要讲述流行的爬虫框架Scrapy ,并以Scrapy 与Selenium、Splash、Redi s 结合的项目案例,深层次了解Scrapy 的使用,还介绍了爬虫的上线部署、如何自己动手开发一款爬虫框架、反爬虫技术的解决方案等内容。

《Python 3网络爬虫开发实战》PDF+源代码+崔庆才
《Python 3网络爬虫开发实战》PDF,606页,带目录和书签,文字可以复制,崔庆才编著,配套源代码。
下载: https://pan.baidu.com/s/1pLo9lpMLODHEJH8zOTNzPw
提取码: nvxe

对爬虫各方法的内容都有涉及,而且内附理论解释详尽,代码即可实现。推荐所有对爬虫有兴趣或从业人员细细研读。学习了三章:第2章介绍了学习爬虫之前需要了解的基础知识,如HTTP、爬虫、代理的基本原理、网页基本结构等内容,对爬虫没有任何了解的建议好好了解这一章 的知识。第3章介绍了最基本的爬虫操作,一般学习爬虫都是从这一步学起的。这一章介绍了最基本的两个请求库(urllib和requests)和正则表达式的基本用
法。学会了这一章,就可以掌握最基本的爬虫技术了。第4章介绍了页解析库的基本用法,包括Beautiful Soup、XPath、pyquery的基本使用方法,它们可以使 得信息的提取更加方便、快捷,是爬虫必备利器。
一旦你开始抓取网页,就会感受到浏览器为我们做的所有细节。网页上如果没有 HTML 文本格式层、CSS 样式层、JavaScript 执行层和图像渲染层,乍看起来会有点儿吓人,学习如何在不借助浏览器帮助的情况下格式化和理解数据。 首先向网络服务器发送 GET 请求(获取网页内容的请求)以获取具体网页,再从网页中读取 HTML 内容,最后做一些简单的信息提取。
瑞安《Python网络爬虫权威指南第2版》中文PDF+英文PDF+源代码
《Python网络爬虫权威指南第2版》中文PDF,266页,带目录,文字可复制;英文PDF,306页,带书签,文字可复制;配套源代码。
下载: https://pan.baidu.com/s/1LPFT-Uho-1LbwjbjcyBe9g
提取码: 7bmx
学习网络爬虫,解决一些问题,主要涉及以下几个方面:
- 解析复杂的HTML页面
- 使用Scrapy框架开发爬虫
- 学习存储数据的方法
- 从文档中读取和提取数据
- 清洗格式糟糕的数据
- 自然语言处理
- 通过表单和登录窗口抓取数据
- 抓取JavaScript及利用API抓取数据
- 图像识别与文字处理
- 避免抓取陷阱和反爬虫策略
- 使用爬虫测试网站

《用Python写网络爬虫第2版》PDF+源代码
《用Python写网络爬虫第2版》中文PDF,212页,带书签目录,文字可以复制;英文PDF,215页,带书签目录,文字可以复制;配套源代码。
下载: https://pan.baidu.com/s/1b5xYKuxRyjLF9y43mJJg6g
提取码: z9zu
《用Python写网络爬虫第2版》包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据抓取,如何利用不同的方式从动态网站中抽取数据,如何使用叔叔及导航等表达进行搜索和登录,如何访问被验证码图像保护的数据,如何使用 Scrapy 爬虫框架进行快速的并行抓取,以及使用 Portia 的 Web 界面构建网路爬虫。

李斌《精通Python爬虫框架Scrapy》PDF中英文+源代码
《精通Python爬虫框架Scrapy》中文PDF,364页,带目录,文字可复制;英文PDF,270页,带目录,文字可以复制;配套源代码。
下载: https://pan.baidu.com/s/1YKt-MEINzBo1AHgNM8JHLg
提取码: 9idg
Scrapy是使用Python开发的一个快速、高层次的屏幕抓取和Web抓取框架,用于抓Web站点并从页面中提取结构化的数据。《精通Python爬虫框架Scrapy》以Scrapy 1.0版本为基础,讲解了Scrapy的基础知识,以及如何使用Python和三方API提取、整理数据,以满足自己的需求。

米切尔《Python网络数据采集》PDF+代码
《Python网络数据采集》高清中文PDF,224页,带目录和书签,能够复制;高清英文PDF,255页,带目录和书签,能够复制;中英文两版可以对比学习。配套源代码。
下载: https://pan.baidu.com/s/1iaQcjSwi3SvKFgYFQ7BOJw
提取码: b98q
适合爬虫入门的书籍《Python网络数据采集》,采用简洁强大的Python语言,介绍了网络数据采集,并为采集新式网络中的各种数据类型提供了全面的指导。第一部分重点介绍网络数据采集的基本原理:如何用Python从网络服务器请求信息,如何对服务器的响应进行基本处理,以及如何以自动化手段与网站进行交互。第二部分介绍如何用网络爬虫测试网站,自动化处理,以及如何通过更多的方式接入网络。

《精通Scrapy网络爬虫》PDF+《从零开始学Python网络爬虫》PDF代码
《从零开始学Python网络爬虫》PDF,279页,带书签,文字可复制,作者: 罗攀 / 蒋仟 ;配套源代码PPT。
《精通Scrapy网络爬虫》PDF,254页,带书签目录,文字可以复制,作者: 刘硕。
下载: https://pan.baidu.com/s/14ygTfntXAajGlLc7rAbBiQ
提取码: usx4
《精通Scrapy网络爬虫》基于Python3,深入系统地介绍了Python流行框架Scrapy的相关技术及使用技巧。《从零开始学Python网络爬虫》不仅有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。

上野宣《图解HTTP 》PDF+《网络是怎样连接的》PDF
《图解HTTP》中文PDF,241页,带目录,文字可复制。《网络是怎样连接的》,计算机网络图解趣味版,中文PDF,362页,带目录,文字可复制。
下载: https://pan.baidu.com/s/193LRr20rE5xUsGebMiusIg
提取码: vx5s
从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。

肖佳《HTTP抓包实战》PDF
《HTTP抓包实战》PDF,210页,带目录,文字可复制。
下载: https://pan.baidu.com/s/1OByT2aLl5LiIrioB_gEOIg
提取码: ra29
做web服务端开发的经常和http协议打交道,《HTTP抓包实战》由浅入深,循序渐进,内容充实 ,不管是新手和老手都适合。里面对http的讲解非常详细,全面的讲解了http起始行、首部、body 的构成。配合fiddler抓包工具让你更好的理解http协议。
对于fiddler这款工具,里面也全面的介绍了它的使用,配合截图,让你一步一步熟悉fiddler的操作。

HTTPS《深入浅出HTTPS从原理到实战》PDF+代码
《深入浅出HTTPS从原理到实战》PDF,515页,带目录,文字可复制。配套源代码。
下载: https://pan.baidu.com/s/1207uocsVo0_pN_qg86-uAg
提取码: yh82
构建一个HTTPS网站,并使网站安全性和性能最大化,对于大型网站的HTTPS系统架构和应用架构设计也有指导意义。

Martin Fowler《重构改善既有代码的设计第2版》中文PDF+英文PDF
《重构改善既有代码的设计第2版》中文PDF,496页,带书签目录,文字可以复制;英文PDF,455页,带书签目录,文字可以复制。译者: 熊节 / 林从羽
下载: https://pan.baidu.com/s/1_hjAkDnudDtUNuSN6NL6xw
提取码: gcsd
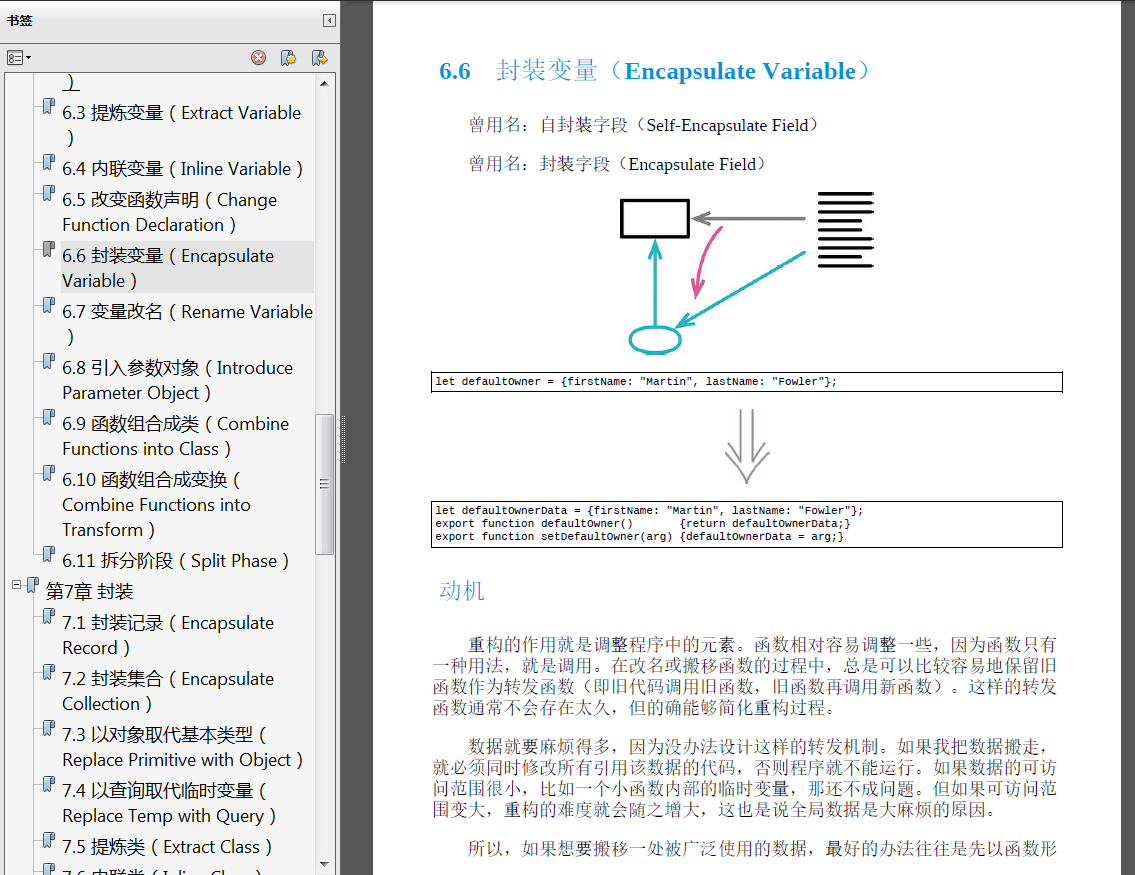
重构是编程的基础,是在不改变外部行为的前提下,有条不紊地改善代码。编程爱好者都知道,Martin Fowler 的《重构:改善既有代码的设计》已经成为全球有经验的程序员手中的利器,既可用来改善既有代码的设计、提升软件的可维护性,又可用于使既有代码更易理解、焕发出新的活力。
理解重构的过程和重构的基本原则;
快速有效地应用各种重构手法,提升程序的表达力和可维护性;
识别代码中能指示出需要重构的地方的“坏味道”;
深入了解各种重构手法,每个手法都包含解释、动机、做法和范例4 个部分;
构建稳固的测试,以支持重构工作的开展;
理解重构过程的权衡取舍以及重构存在的挑战等。

原文链接:https://www.cnblogs.com/wyprog/p/13280464.html

点击排行
站长推荐



猜你喜欢


打赏本站
- 如果你觉得本站很棒,可以通过扫码支付打赏哦!
- 微信扫码:你说多少就多少~

- 支付宝扫码:你说多少就多少~
